

- Kafka and Pulsar are commonly used for creating work queues, which involve publishing a message to be consumed by a cluster of processes for longer periods of processing time.
- Work queues require distributing processing across many different processes and computers, making the task more complex.
- Examples of work queues include video transcoding and voice recognition and sentiment analysis for call centers.
- The initial difficulty of work queues is balancing the work and scaling the cluster, while the more difficult issue is dealing with errors.
- Real-time systems are preferred over batch systems for work queues due to the speed of results.
A common use case for using Kafka and Pulsar is to create work queues. The two technologies offer different implementations for accomplishing this use case. I’ll discuss the ways of implementing work queues in Kafka and Pulsar as well as the relative strengths of doing each one.
What are work queues?
A work queue is using a messaging technology to add a unit of work by publishing out a message. This message would be consumed by another process – ideally a cluster of processes – and then do some kind of work on it.
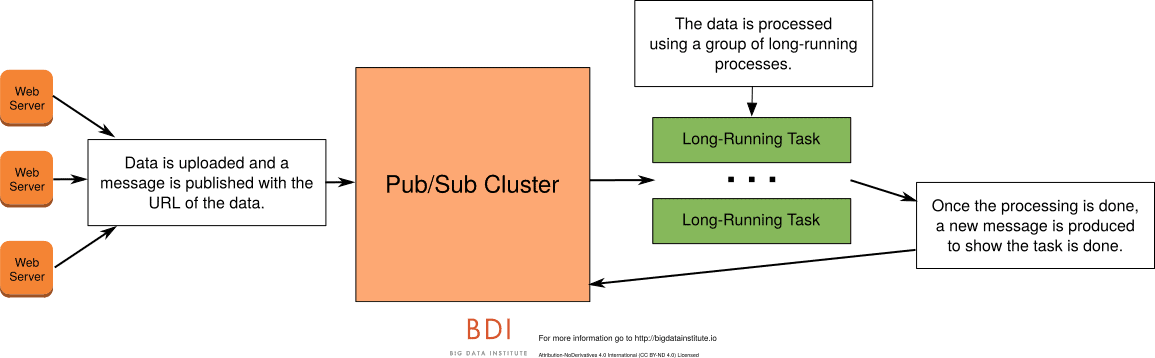
A work queue differs from other processing in the amount of time it takes. Most regular processing – like ETL or simple processing – of data should be measured in milliseconds or a second at the high end. A work queue will process for a much longer period of time that is measured in the seconds to minutes to hours.
This is also called a distributed work queue. This is because a single machine or process isn’t enough to keep up with the demand. We have to distribute this processing across many different processes and computers. With this need for distributed technologies, the complexity of the task increases 10-15x.
Examples of work queues
To help you understand a work queue, let me give you a few simple examples I’ve seen in the real-world. The common thread to all examples is the need to process for a longer period of time and get the result as soon as possible.
Video Transcoding
Some use cases require that a video be uploaded by a user. This video will be saved to bucket storage. Once the video is uploaded, the web service will publish a message that will be consumed by a cluster of consumers. The message would contain the bucket URL of the video to be transcoded. These consumers will transcode or prepare the video for use in web-friendly format. The transcoding will take minutes to hours to finish. Once the video is done, the transcoding process should publish a message that video is ready.
Voice Recognition and Sentiment Analysis
Some use cases process phone call data for call centers. Once the call is completed, several processes need to happen. First, the call’s voice conversation needs to have voice recognition run to change the audio to text. Next, the text will have various NLP or sentiment analysis run on it. The entire processing will take 1-60 minutes. Once the processing is done, a message needs to be published to flag the conversation or score the conversation.
What’s difficult about work queues?
The initial difficulty is to balance the work. You need to make sure that one long-running process doesn’t back up the rest of the queue. The rest of the work needs to continue unabated. You also need to be able to scale the cluster as more or less flows through.
The more difficult issue of work queues is dealing with errors:
- How do you know when – or if – a process died?
- How do you restart the processing?
- How do you even detect when a process has died?
The answers to these questions are technology-specific. It makes your choice of technology crucial when you’re doing work queues.
Why not batch?
A common question is why should you use real-time and not batch systems? Batch systems will have an inherent spin up time. For a 30 second processing time, you could spend 5-10 seconds just waiting on the distributed system to allocate and spin up the resources. One of the keys for real-time work queues is the speed of results. A batch system is just too inefficient to process this data.
Work Queues with Kafka
Now that you understand work queues and the difficulties associated with them, let’s go specifically into creating work queues with Apache Kafka.
High watermarks and work queues
Before you can understand how to create work queues in Kafka, you’ll need to understand how Kafka consumers mark that they’ve consumed a message. Kafka consumers perform this task by committing an offset. A Kafka consumer uses the commitSync or commitAsync methods. These methods take a Map of topic, partition, and offset as an argument.
Kafka consumers use what’s called a high watermark for consumer offsets. That means that a consumer can only say, “I’ve processed up to this point” rather than, “I’ve processed this message.” That is a crucial distinction in Kafka. Kafka does not a have a built-in way to only acknowledge a single message.
This high watermark for consumer offsets means that errors can’t be found individually. For example, if a consumer were processing two pieces of work from the same partition and one failed, Kafka lacks the built-in ability to say this one failed and this one succeeded. A Kafka client can say I’ve processed up to this point immaterial of success or failure of the individual pieces of work.
To deal with this limitation, you’ll need to treat each partition as it’s own “thread” of work. Each partition will be limited to working on one thing at a time. As a consumer finishes that piece of work, it will call the commitSync to mark that processing as done (raising the high watermark).
Since you’re keeping long-running work in a partition, you’ll have to create far more partitions to process data effectively. Whereas you might have started with 20-30 partitions, you might use to 100 partitions. This number of partitions is for Kafka’s sake, it’s so that the consumer group will have enough partitions to distributed the load effectively.
It may go without saying, but you’ll need to scale your consumer group according to the amount of work you’ll be doing.
Managing your own commits
You’ll notice that I used the word “built-in” in several times. This is because there is another option and it’s not built-in to Kafka. You’ll have to write all of this code and handling will have to be your own.
As you saw, the issue with Kafka consumer is their high watermark limitation. You could start handling your consumers’ offsets programmatically. The easiest way to do this is with a database. You would turn off Kafka’s automatic offset commits. You would do upserts of offsets into the database instead of Kafka. These upserts would be on a per topic, partition, and offset basis as well as the current state.
When a consumer restarted, the consumer would need to know its partition assignments. It would do a database lookup to find the last offset and its state. If there was an error with the last offset, the consumer would start processing that message.
While this adds more programming overhead, this is the method I recommend when I work with teams.
Work queues with Pulsar
Now that you’ve seen how to create work queues with Kafka, let’s see how Apache Pulsar compares.
Selective acking in Pulsar
We learned before about Kafka’s high watermark acking. Pulsar supports that type of acknowledgement and another type called selective acknowledgement. Selective acknowledgement allows a consumer to only acknowledge an individual message. You can learn more about selective acknowledgement.
When it comes to work queues, selective acknowledgments really change the game. With a work queue, we’re able to acknowledge that we’ve processed just that message. To do this, we’ll use the acknowledge method.
To get messages that have failed, you would call the redeliverUnacknowledgedMessages method. This will have Pulsar redeliver all unacknowledged messages. Another setting called ackTimeout will automatically redeliver all messages that exceed the timeout.
There’s another benefit to work queues that I didn’t talk about before. Even with many different partitions, it’s still possible for a few partitions to hotspot or receive an inordinate amount of work. Pulsar solves this issue better with shared subscriptions. Shared subscriptions allow for a round robin distribution across consumers. This would allow for a more even distribution of work than is possible in Kafka.
For a work queue in Pulsar, you would publish a message. This message would be consumed by a shared subscription on one out of many different consumer processes. The consumer would kick off the actual processing of data. Once that processing is done, the consumer would selectively acknowledge the message. It would produce a message that the processing was finished.
Note: Pulsar was designed to do work queue as a specific use case. It was used at Yahoo for this purpose. That’s the big reason we’re seeing such a big difference.
Creating a Distributed Work Queue
Your choice of messaging technology really changes how you implement a distributed work queue. While it is possible to create work queues with either solution, Kafka and Pulsar have different ways of creating them. It’s much easier to create distributed work queues with Pulsar.
If you have a work queue use case, make sure you get it right. These use cases are difficult to code and handle the operational issues associated with them.