

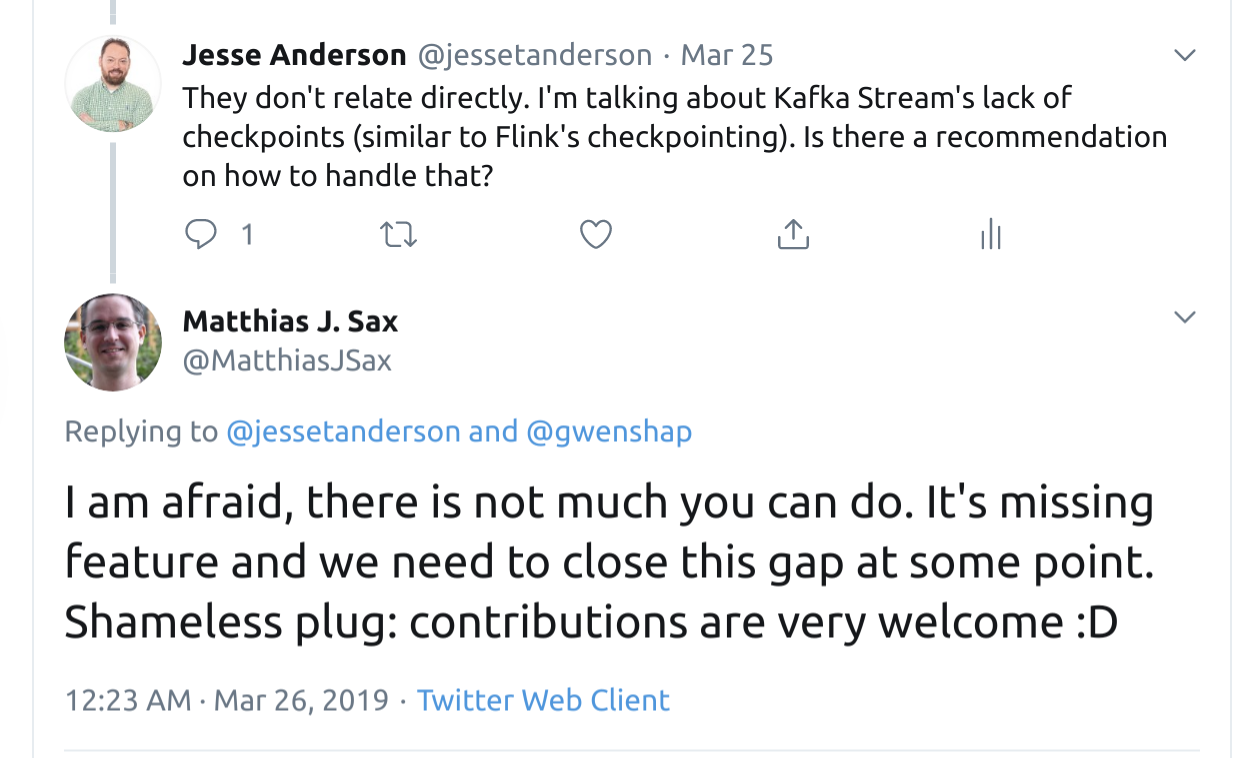
- Implementing checkpointing in processing frameworks like Flink is crucial for ensuring quick recovery and minimal downtime in distributed systems.
- The lack of checkpointing in Kafka Streams can result in hours of downtime in case of failures, impacting the reliability and availability of the system.
- Kafka Streams lacks proper checkpointing mechanisms, making it unsuitable for critical real-time systems due to the risk of extended downtime.
- Checkpointing is fundamental for operating distributed systems, and Kafka Streams lacks this feature, leading to potential issues with state recovery and downtime.
- Kafka is a messaging system, not a database, and using it as such can lead to challenges with state management and recovery in case of failures.
Update: Confluent has renamed KSQL to ksqlDB
It’s that Kafka Summit time of year again. There are lots of announcements. Some are good and some you have to sift through in order to figure out what’s the best for you and your organization.
I’ll briefly state my opinions and then go through my opinions and the technical reasons in more depth.
I recommend my clients not use Kafka Streams because it lacks checkpointing. Kafka Streams also lacks and only approximates a shuffle sort. KSQL sits on top of Kafka Streams and so it inherits all of these problems and then some more.
Kafka isn’t a database. It is a great messaging system, but saying it is a database is a gross overstatement. Saying Kafka is a database comes with so many caveats I don’t have time to address all of them in this post. Unless you’ve really studied and understand Kafka, you won’t be able to understand these differences.
I find talks and rebuttals like this don’t really separate out opinions from facts. I’m going to try to separate out my opinion from the facts. I feel like Confluent’s slide content should have *, †, ‡, §, ‖, ¶ after every statement so that you can look up all of the caveats they’re glossing over.
Checkpointing
It’s a fact that Kafka Streams – and by inheritance KSQL – lacks checkpointing:
That sounds esoteric and me being pedantic right?
Checkpointing is fundamental to operating distributed systems. Let me explain what checkpointing is.Checkpointing is fundamental to operating distributed systems.
Kafka is a distributed log. You can replay any message that was sent by Kafka. For message processing, it can be stateless or stateful. For stateless processing, you just receive a message and then process it. As soon as you get stateful, everything changes. Now, you have to deal with storing the state and storing state means having to recover from errors while maintaining state.
For Kafka Streams, they say no problem, we have all of the messages to reconstruct the state. They even say that you can use a compacted topic to keep the messages stored in Kafka to be limited to the ~1 per key.
Solved right? No, because ~1 message per key can still be a massive amount of state. If you have 100 billion keys, you will 100 billion+ messages still in the state topic because all state changes are put into the state change topic. If you have a growing number of keys, the size of your state will gradually increase too.
The operational manifestation of this is that if a node dies, all of those messages have to be replayed from the topic and inserted into the database. It’s only once all of these mutations are done that the processing can start again.
In a disaster scenario – or human error scenario – where all machines running the Kafka Streams job die or are killed, all nodes will have to replay all state mutation messages before a single message can be processed.
This replaying of state mutation messages could translate into hours of downtime. Some potential users of Kafka Streams have told me they calculated this scenario out to be 4+ hours of downtime. Now you’re 4+ hours behind and still have to process all of the messages that accrued over that time just to get back to the current time.
For this reason, databases and processing frameworks implement checkpointing (in Flink this is called snapshots). This is where the entire state at that point in time is written out to durable storage (S3/HDFS). When there is a massive error, the program will start up, read the previous checkpoint, replay any messages after the checkpoint (usually in the 1000s), and start processing again. Overall, this process will take seconds to minutes.
Downtime for systems with checkpointing should be in the seconds to minutes instead of hours with Kafka Streams. Overall, downtime for real-time systems should be as short as possible. Great effort goes into distributed systems to recover from failure as fast as possible.Downtime for systems with checkpointing should be in the seconds to minutes instead of hours with Kafka Streams.
Update: I forgot to talk about one of Kafka Stream’s workaround to a lack of checkpointing. They recommend using a standby replica. I consider this more of a hack than a solution to the problem. It still doesn’t handle the worst-case scenario of losing all Kafka Streams processes – including the standby replica.
Shuffle Sort
Shuffle sort is an important part of distributed processing. It’s the method of bringing data together with the same key. If you’re analytics, chances are that you will need shuffle sorts. If you don’t know what a shuffle sort is, I suggest you watch this video.
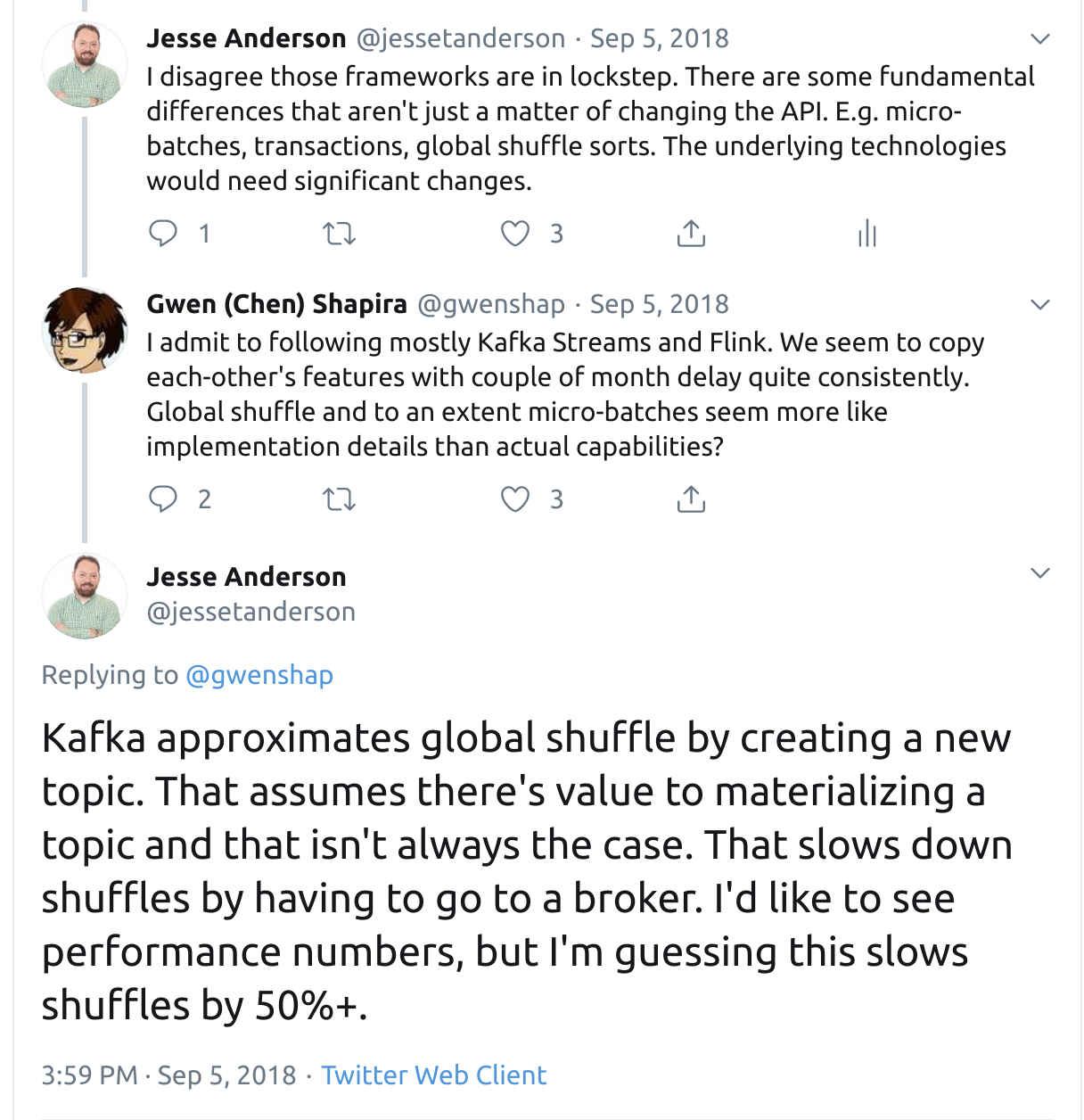
It’s a fact that Kafka Stream’s shuffle sort is different than Flink’s or Spark Streaming’s. The way it works is buried in the JavaDoc (bolding mine):
If a key changing operator was used before this operation (e.g., selectKey(KeyValueMapper), map(KeyValueMapper), flatMap(KeyValueMapper), or transform(TransformerSupplier, String…)), and no data redistribution happened afterwards (e.g., via through(String)) an internal repartitioning topic will be created in Kafka. This topic will be named “${applicationId}-XXX-repartition”, where “applicationId” is user-specified in StreamsConfig via parameter APPLICATION_ID_CONFIG, “XXX” is an internally generated name, and “-repartition” is a fixed suffix. You can retrieve all generated internal topic names via KafkaStreams.toString().
This means that anytime you change a key – very often done for analytics – a new topic is created to approximate the Kafka Streams’ shuffle sort. This method of doing shuffle sorts assumes several things that I talked about in this thread:
I’ve talked to some (former) users of Kafka Streams who didn’t know about this new workaround topic. They blew up their cluster by doing real-time analytics and creating too much load and data on their brokers. They simply thought they were doing some processing.
If performance isn’t a key metric in your system, maybe this is a way to go. However, there are other and much better processing frameworks that have a built-in shuffle sort and work with Kafka like Apache Flink. These systems give you the best of both worlds.
Update: there have been a few questions on shuffle sorts. The broker will save and replicate all data in the internal repartitioning topic. That is a pretty heavyweight operation for something that is considered intermediate and of short-term usage in other systems like Flink. Normally, intermediate data for a shuffle sort is kept for a short period of time.
Kafka Streams and KSQL
Lacking these two crucial features, it makes Kafka Streams unusable from an operational perspective. You can’t have hours of downtime on a production real-time system. You can’t blow up your cluster with shuffle sorts. Unless you run an explain plan before every KSQL query, you won’t know the shuffle sorts (topic creation) that will happen.
It’s for these main reasons that my clients don’t use Kafka Streams or KSQL in their critical paths or in production.
Confluent’s Kafka Summit 2019 Announcements
Confluent made several announcements in their various keynotes. These ranged from their plans for Kafka and KSQL.
Some of these keynotes set up straw man arguments on architectures that aren’t really used. For example, they talked about databases being the place where processing is done. There are some small data architectures and more data warehouse technologies that use the database for processing. However, I haven’t seen a big data architecture repeat these problems. We know they don’t scale. We’re using actual processing engines that can scale to overcome all of these data processing issues. In big data, we’ve been solving these issues for years and without the need for database processing.
They positioned KSQL as being able to take up some workloads being done now by big data ecosystem projects. They pointed to so many ecosystem projects as an issue. There are so many technologies in the big data ecosystem because each one solves or addresses a use case. An organization could eliminate various parts but that would either drastically slow down or eliminate the ability to handle a use case. KSQL – even after these new features – will still be of limited utility to organizations.
That leads you to wonder why Confluent is pushing into new uses. Confluent’s pricing model is already really unpopular with organizations. A pure Kafka company will have difficulty expanding its footprint unless it can do more. They’re having to branch out to increase the market share and revenue. This means they have to try to land grab and say that they are a database.
This messaging includes – in my opinion – incorrect applications of Kafka. Confluent is pushing to store your data forever in Kafka. Kafka is a really poor place to store your data forever. That long-term storage should be an S3 or HDFS. There is a significant performance difference between a filesystem and Kafka. There is a big price difference too.
I encourage architects to look at this difference. There are only 2 ways to access previous data in Kafka by timestamp or by commit id. Normally use cases need random access with a where clause and we’re seeing Confluent try to handle this with KSQL. Database optimization for random access reads is a non-trivial problem and very large companies with large engineering teams are built around this problem.
The reality is this database should either be in the broker process or at the application level with a solid and durable storage layer. In my opinion, an architecture using KSQL for current status using a where clause doesn’t really make sense. There are other proven architectures to get current status of data like a database or using a processor with checkpointing.
At the end of the keynote, they talked about not wanting to replace all databases. I expect this message to change. We’ll start to see more and more database use cases where Confluent pushes KSQL as the replacement for the database. You should know that creating a database is a non-trivial thing and creating a distributed database is extremely difficult.
What Should You Do?
The point of this post is not to discourage use of Kafka. Kafka is a great publish/subscribe system – when you know and understand its uses and limitations. Rather, the point is to use Kafka correctly and not based on a company’s marketing. Remember that vendors don’t always have their customers’ best interests in mind. Their focus is to increase revenues and product usage. These new ways of using a product may or may not be in your organization’s best interests.
As you decide to start doing real-time, make sure that you have a clear and specific business case that going from batch to real-time makes. This business case could be current or in the future. If you don’t establish this business value upfront, you could be creating more problems for yourselves that you ever had.
Finally, you should know the architectural limitations of Kafka. Some of these are buried or you need a deep understanding of distributed systems to understand them. Make sure the person creating your architecture really understands these implications on your organization and use case. Otherwise, you’ll be implementing someone else’s vision and painting yourself into an operational corner.